Traditional AI, or rule-based AI, relies on predefined logic and structured rules to process information and make decisions. It uses symbolic representation, where concepts like numbers, words, or objects are manipulated through logical inference.
These systems are highly interpretable, as reasoning is based on clear "IF-THEN" rules. For example, a medical diagnosis system may follow: IF fever AND cough, THEN flu.
Knowledge representation in traditional AI is structured using semantic networks (graphs connecting related concepts) or frames (data structures with attributes and values). These methods help organize and process relationships, enabling efficient problem-solving and decision-making.

Traditional AI expert systems leverage symbolic AI to replicate human decision-making. These systems consist of two key components:
- Knowledge Base: Stores domain-specific rules and facts.
- Inference Engine: Applies these rules to input data to derive conclusions.
Process Flow
The process starts with user input, where data or queries are provided. The knowledge base, structured with symbolic and logical representations, holds predefined rules and facts.
As depicted in the diagram, the inference engine retrieves relevant rules and facts from the knowledge base to interpret user input. It then performs data parsing, preprocessing, rule matching, and inference-making. This process is iterative, continuously refining intermediate results by consulting the knowledge base until an optimal solution is reached. Breaking down complex queries into smaller components ensures context-specific and accurate outputs.
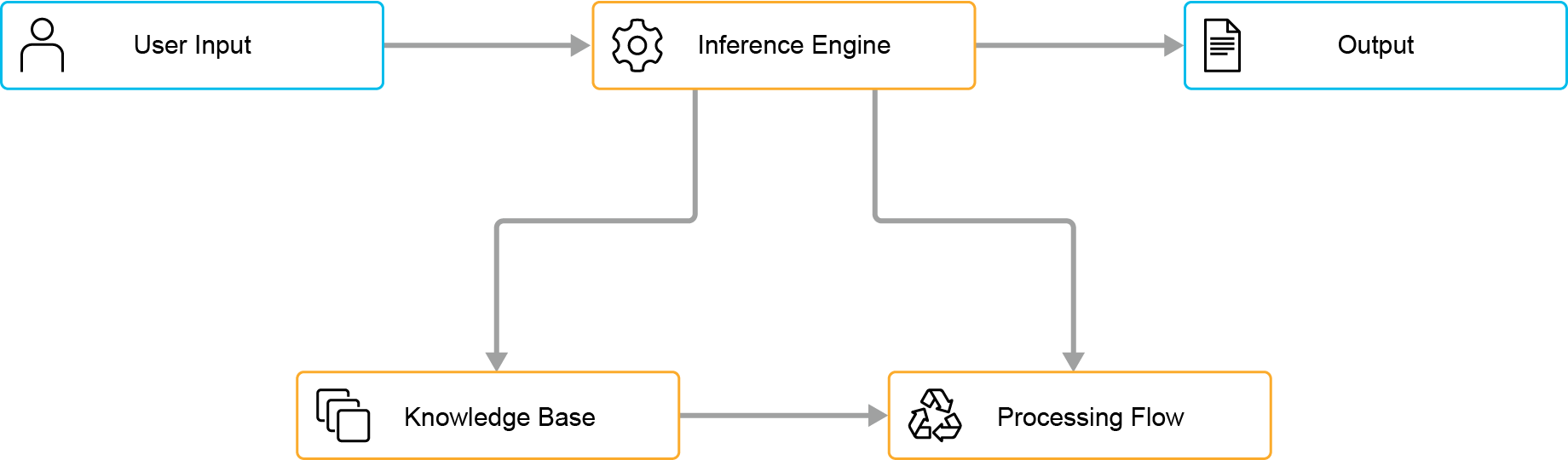
Finally, the system presents its conclusions or decisions as output, delivering responses or actions based on logical analysis of the input data and predefined rules.
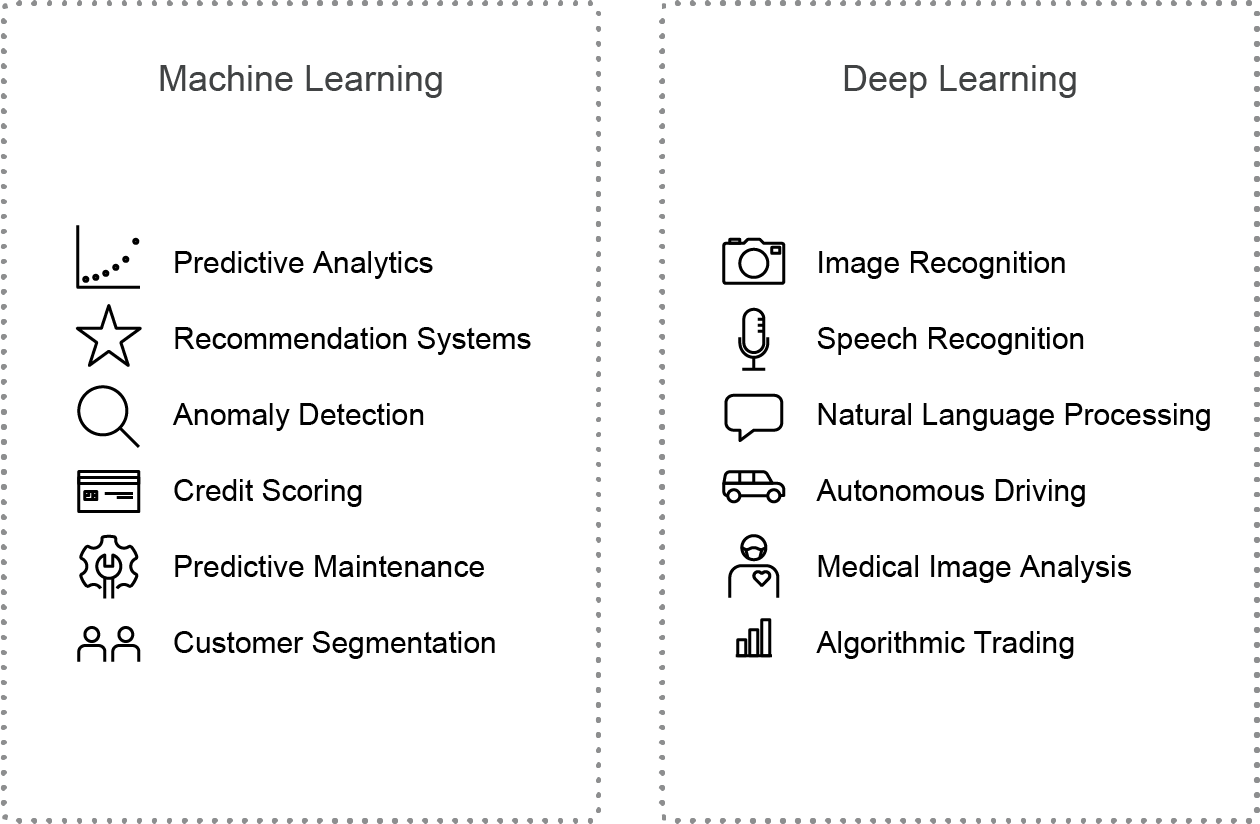
So what is machine learning? What's the difference between deep learning?
Machine learning (ML) and deep learning (DL) are key branches of modern AI, each employing distinct methods to analyze and learn from data. Understanding their differences is essential for developers and businesses to choose the right approach for their needs. Additionally, this knowledge fosters innovation, enabling the creation of hybrid models that leverage the strengths of both ML and DL. For example, an ML system can handle data preprocessing and feature selection, while DL can be applied to recognize complex patterns and enhance predictive accuracy.
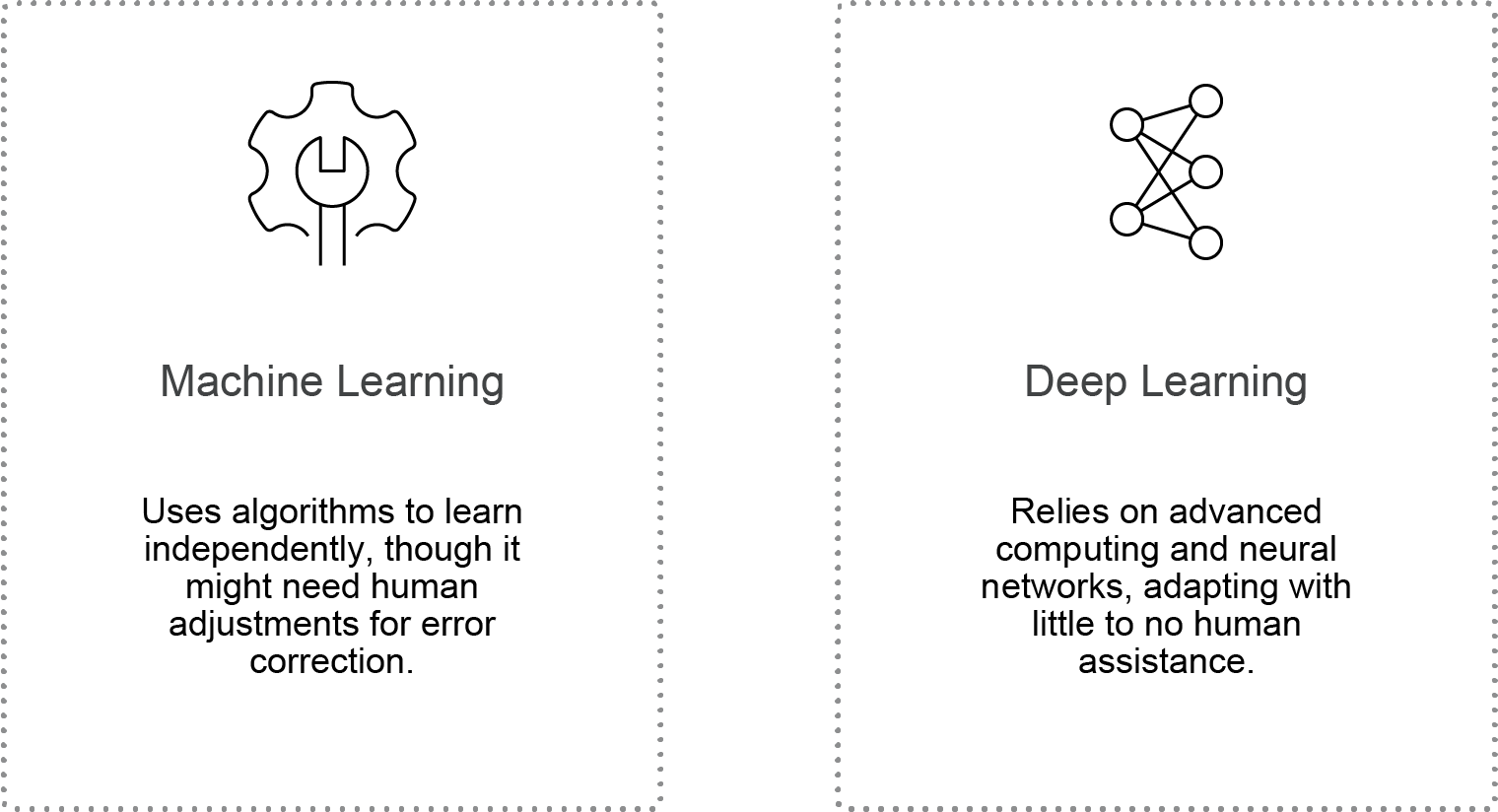
Data Requirements: ML vs. DL
Machine learning (ML) works well with structured data and requires fewer data points, making training faster and less resource-intensive. Tasks like house price prediction or email filtering can be trained in minutes to hours. ML models are also easier to interpret, making them suitable for cases with limited data. However, they struggle with unstructured data like images or speech.
Deep learning (DL) demands large datasets, especially for unstructured data such as images, audio, and text. Processing unstructured data takes longer, requiring extensive computational power. Training DL models for tasks like speech recognition can take days to weeks. Additionally, DL models operate within complex neural networks, making their decisions harder to interpret.
Techniques and Methodologies
ML vs. DL Techniques and Methodologies
Machine Learning (ML) includes various techniques suited to different applications:
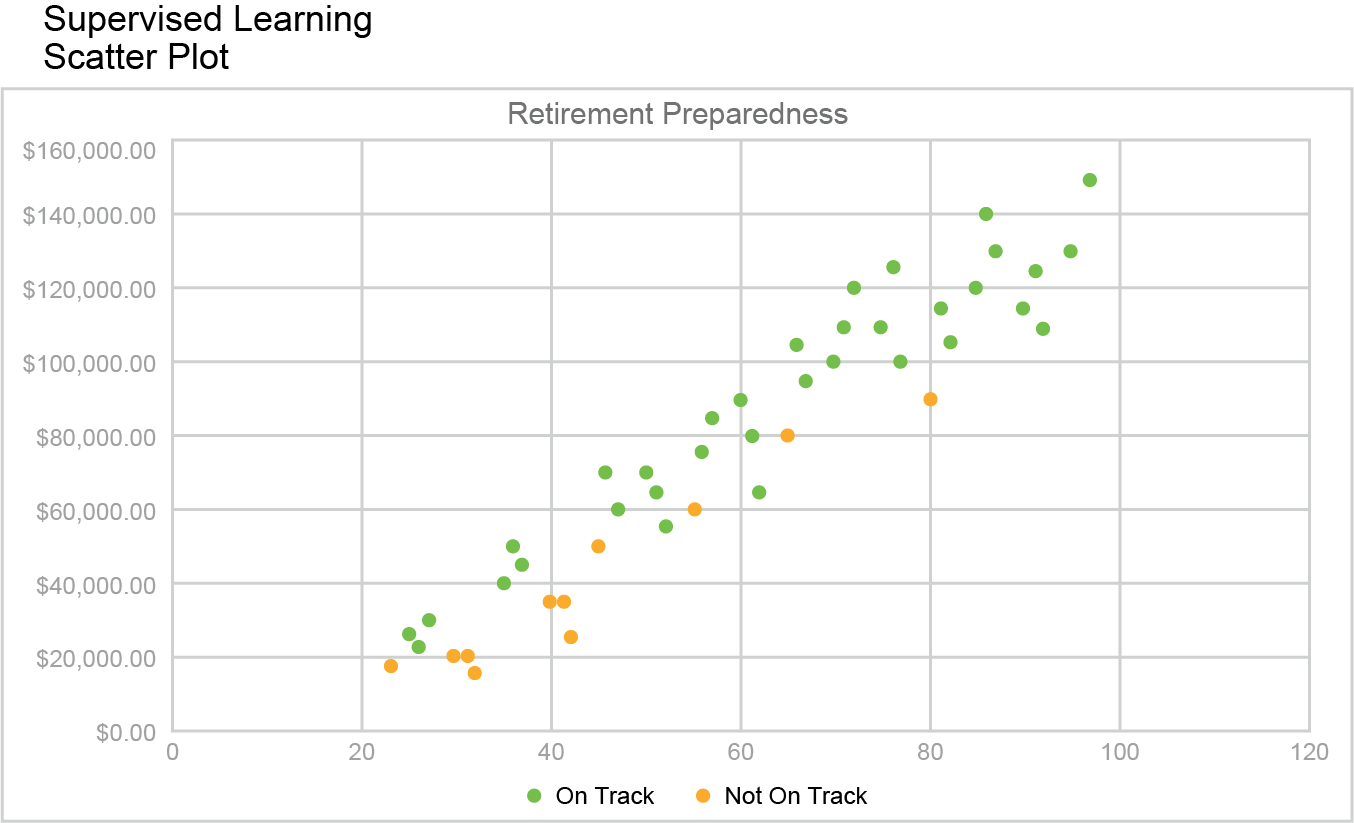
- Supervised Learning: Trains models on labeled data, using methods like regression and classification to predict outcomes. Example: A retirement preparedness model learns from labeled data (age, account balance) to classify individuals as "On Track" or "Not on Track."
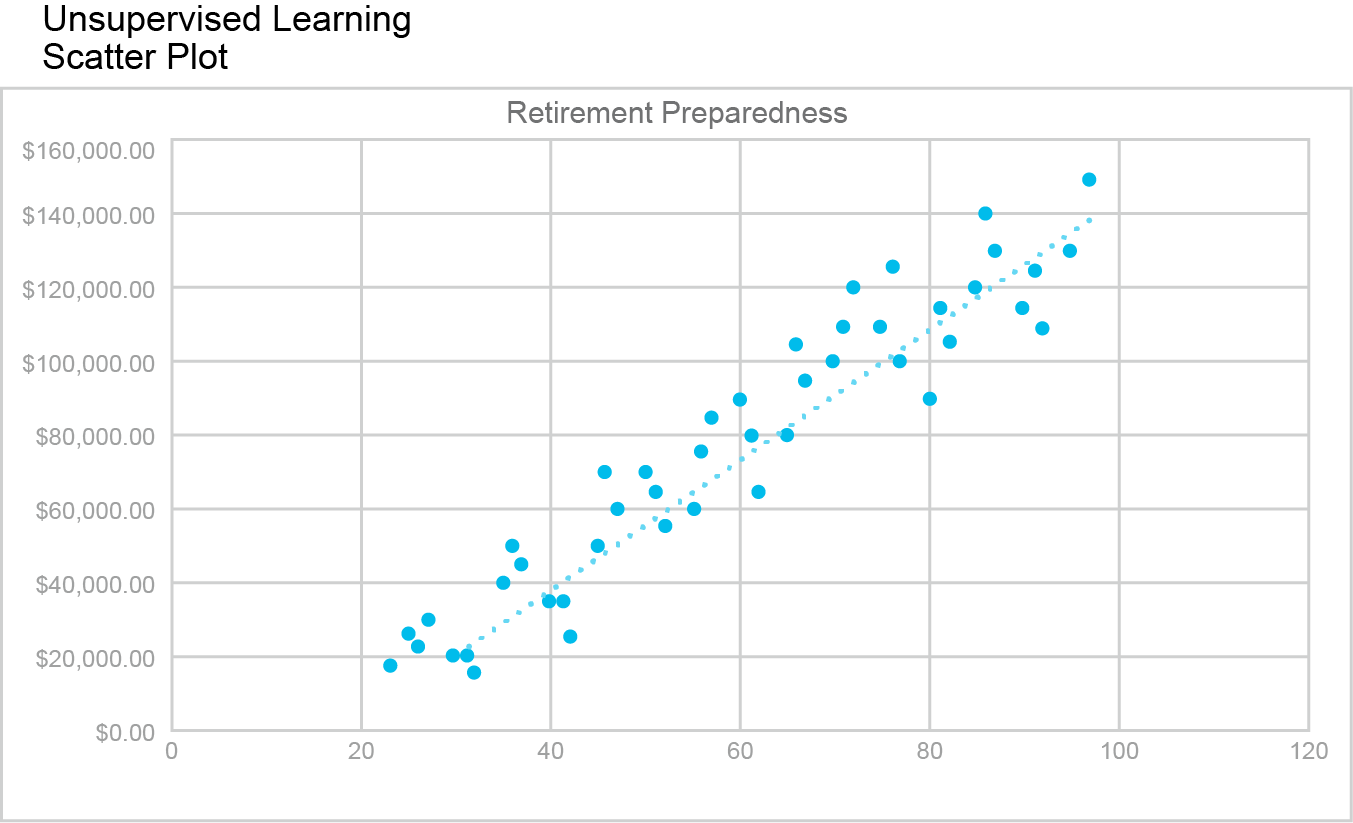
- Unsupervised Learning: Works with unlabeled data to find hidden patterns. Techniques like clustering help identify groups based on similarities without predefined labels. Example: Grouping individuals based on retirement savings trends. Some techniques in unsupervised learning include clustering and dimensionality reduction
- Reinforcement Learning: Models learn by interacting with an environment and receiving rewards or penalties. Used in robotics, gaming, and autonomous systems. Example: An AI playing a video game learns by maximizing its score.
- Deep Learning (DL): Uses multi-layered neural networks to extract features from large datasets. It blends supervised and unsupervised learning, improving predictions by generating pseudo-labels for new data and refining accuracy through iterative training.
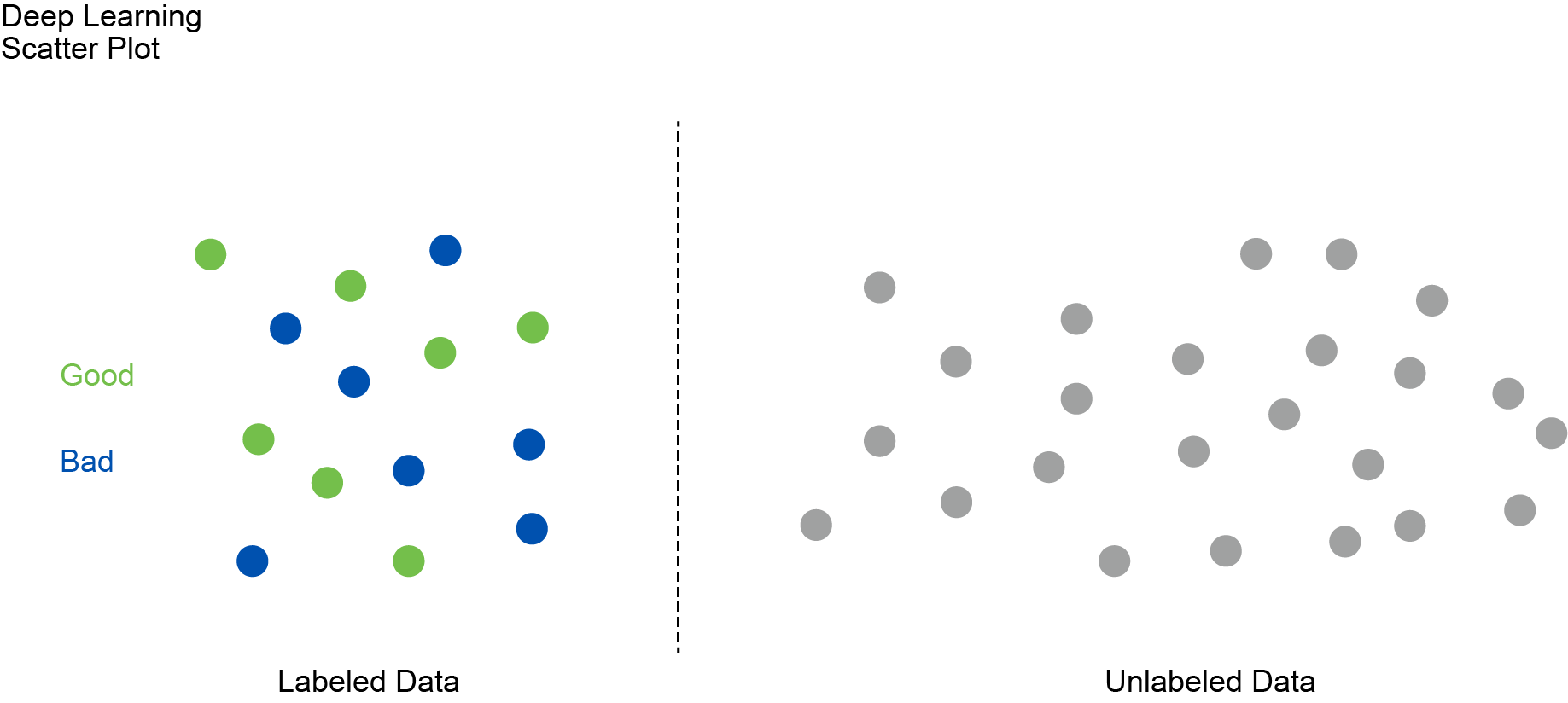
DL models use neural networks with multiple layers to learn from large datasets. These networks consist of interconnected nodes, or neurons, which are organized into layers. Each layer processes the input data and passes the output to the next layer, allowing the model to learn complex representations of the data. This deep structure enables the model to automatically extract features from raw data, reducing the need for manual feature-engineering.
In an approach blending supervised and unsupervised learning, a DL model first learns from the labeled data in the preceding figure to identify patterns and relationships that distinguish "Good" instances from "Bad" ones. This initial training phase uses techniques like backpropagation and gradient descent to minimize the error between the model's predictions and the actual labels. During this phase, the model goes through multiple epochs, each representing one complete pass through the labeled dataset. These epochs are essential as they allow the model to adjust its weights and improve its accuracy iteratively.
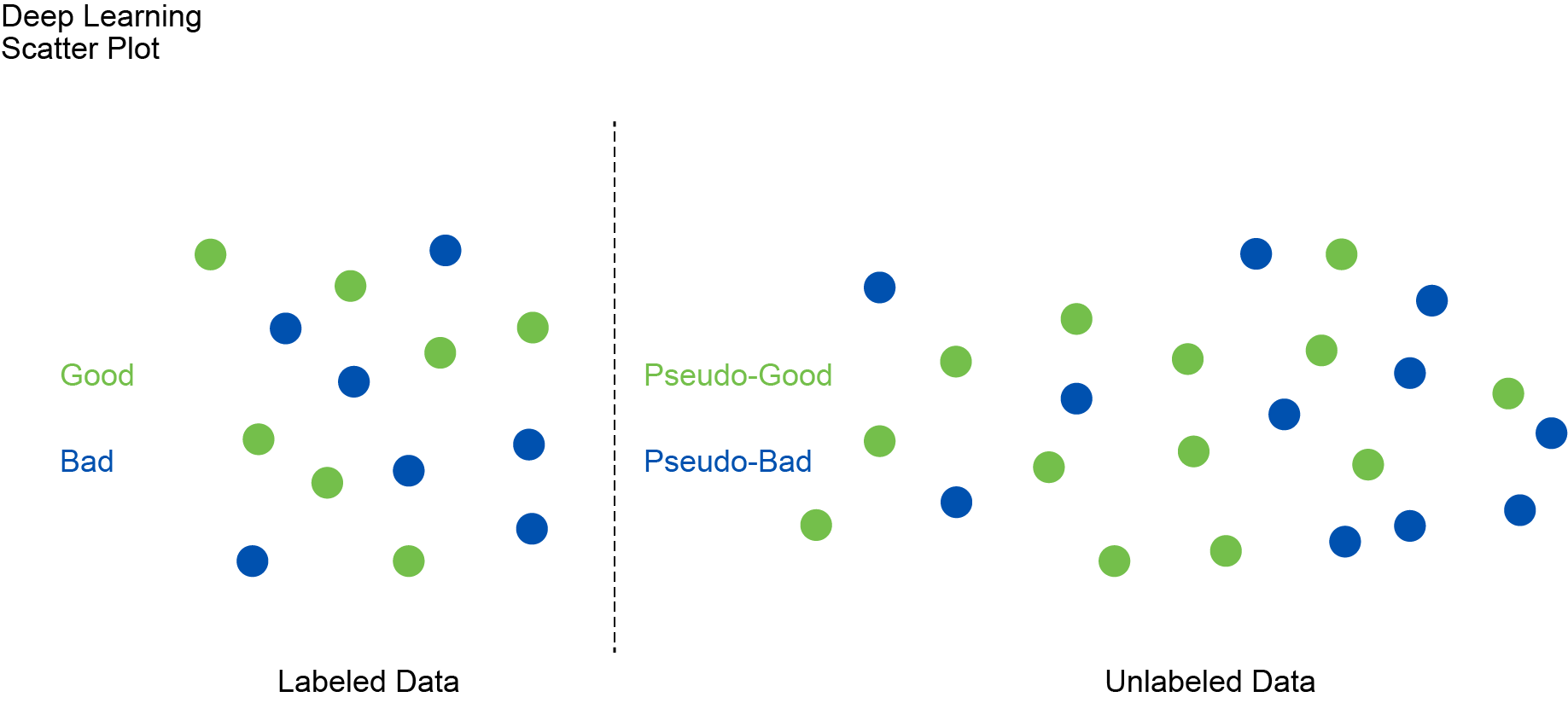
After the initial training, the model is used to predict labels for some new or novel unlabeled data. These predictions are referred to as pseudo-labels because they aren’t verified yet but are instead generated based on the model's current understanding of what separates “good†and “bad.â€After the initial training, the model is used to predict labels for some new or novel unlabeled data. These predictions are referred to as pseudo-labels because they aren’t verified yet but are instead generated based on the model's current understanding of what separates “good†and “bad.â€
Next, the pseudo-labeled data is combined with the original labeled data to create a new epoch of an expanded training set. This expanded set includes both the original labeled examples and the newly pseudo-labeled examples. The model then undergoes additional training using this expanded dataset. During this phase, the model refines its predictions by adjusting its parameters to minimize errors across both labeled and pseudo-labeled data. This process can be repeated many times to refine and improve the accuracy of the results.
What are the distinct applications they can be used for?